MongoDB
MongoDB is an open-source, non-relational database developed by MongoDB, Inc. MongoDB stores data as documents in a binary representation called BSON (Binary JSON). Related information is stored together for fast query access through the MongoDB query language. Fields can vary from document to document; there is no need to declare the structure of documents to the system – documents are self-describing. If a new field needs to be added to a document, then the field can be created without affecting all other documents in the collection, without updating a central system catalog, and without taking the system offline. Optionally, schema validation can be used to enforce data governance controls over each collection.
According to Wikipedia:
MongoDB (from humongous) is a cross-platform document-oriented database. Classified as a NoSQL database, MongoDB eschews the traditional table-based relational database structure in favor of JSON-like documents with dynamic schemas (MongoDB calls the format BSON), making the integration of data in certain types of applications easier and faster. Released under a combination of the GNU Affero General Public License and the Apache License, MongoDB is free and open-source software.
Why MongoDB?
- Rich Object Model: MongoDB supports a rich and expressive object model. Objects can have properties and objects can be nested in one another (for multiple levels). This model is very “object-oriented” and can easily represent any object structure in your domain. You can also index the property of any object at any level of the hierarchy — this is brilliantly powerful!
- Secondary Indexes: Indexes speed up the queries significantly, but they also slow down writes. Secondary indexes are a first-class construct in MongoDB. This makes it easy to index any property of an object stored in MongoDB even if it is nested. This makes it really easy to query from the database based on these secondary indexes.
- Native Aggregation: MongoDB has a built-in Aggregation framework to run an ETL(Extract, transform and load) pipeline to transform the data stored in the database. This is great for small to medium jobs but as your data processing needs become more complicated the aggregation framework becomes difficult to debug.
- Schema-less Models: MongoDB, allows you to not enforce any schema on your documents. While this was the default in prior versions, in the newer version you have the option to enforce a schema for your documents. Each document in MongoDB can have a different structure and it is up to your application to interpret the data. While this is not relevant to most applications, in some cases the extra flexibility is important. Schema-less models mean that documents in the same collection do not need to have the same set of fields or structure, and common fields in a collection’s documents may hold different types of data.
Key Features
High Performance
MongoDB provides high-performance data persistence. In particular,
- Support for embedded data models reduces I/O activity on the database system.
- Indexes support faster queries and can include keys from embedded documents and arrays.
Rich Query Language
MongoDB supports a rich query language to support read and write operations (CRUD) as well as:
- Data Aggregation
- Text Search and Geospatial Queries.
High Availability
MongoDB’s replication facility, called replica set, provides:
- automatic failover
- Data redundancy.
A replica set is a group of MongoDB servers that maintain the same data set, providing redundancy and increasing data availability.
Horizontal Scalability
MongoDB provides horizontal scalability as part of its core functionality:
- Sharding distributes data across a cluster of machines.
- Starting in 3.4, MongoDB supports creating zones of data based on the shard key. In a balanced cluster, MongoDB directs reads and writes covered by a zone only to those shards inside the zone.
Support for Multiple Storage Engines
MongoDB supports multiple storage engines:
- WiredTiger Storage Engine (including support for Encryption at Rest)
- In-Memory Storage Engine
- MMAPv1 Storage Engine(Deprecated in MongoDB 4.0)
In addition, MongoDB provides pluggable storage engine API that allows third parties to develop storage engines for MongoDB.
Structural aspects of MongoDB
1. Data Model
MongoDB stores data in the form of BSON -Binary encoded JSON documents which supports a rich collection of types. Fields in BSON documents may hold arrays of values or embedded documents. In MongoDB, a database construct is a group of related collections. Each database has a distinct set of data files and can contain a large number of collections. A single MongoDB deployment may have many databases.
What is a ‘document’ in Mongo DB?
A record in MongoDB is a document (shown below), which is a data structure composed of field and value pairs. MongoDB documents are similar to JSON objects. The values of fields may include other documents, arrays, and arrays of documents. This is an important differentiation from RDBMS systems where each field must contain only one value.


What are ‘collections’ in Mongo DB?
MongoDB stores documents in collections (shown below).Collections are analogous to tables in relational databases. In RDMS all tables in a database must have the same schema, but in MongoDB, there is no such requirement. This schema-less design is an innovation which makes MongoDB the most used NoSQL Database. However, documents stored in a collection must have a unique_id field that acts as a primary key.
2. Sharding
Database systems with large data sets and high throughput applications can challenge the capacity of a single server in multiple ways such as:
- High query rates put stress on the CPU capacity of the server.
- Larger data sets exceed the storage capacity of a single machine.
- Dataset sizes larger than the system’s RAM stress the I/O capacity of disk drives.
To address these issues of scale, database systems have two basic approaches:
- Vertical Scaling
- Sharding or Horizontal Scaling
3. Data partitioning
MongoDB distributes data at the collection level. Sharding partitions a collection’s data by the shard key.
What is a shard key?
A shard key is either an indexed field or an indexed compound field that exists in every document in the collection. MongoDB divides the shard key values into chunks and distributes the chunks evenly across the shards. To divide the shard key values into chunks, MongoDB uses either range based partitioning or hash-based partitioning.
4. Aggregation
Aggregations are operations that process data records and return computed results. Unlike queries, aggregation operations in MongoDB use collections of documents as an input and return results in the form of one or more documents. MapReduce is a tool used for aggregating data.
What is an Aggregation Pipeline?
An aggregation pipeline is a series of document transformations which are executed in stages. The original input is a collection whereas the output can be a document, cursor or a collection.
The most basic pipeline stages provide filters that operate like queries and document transformations that modify the form of the output document. Other pipeline operations provide tools for grouping and sorting documents by specific field or fields as well as tools for aggregating the contents of arrays, including arrays of documents. In addition, pipeline stages can use operators for tasks such as calculating the average or concatenating a string.
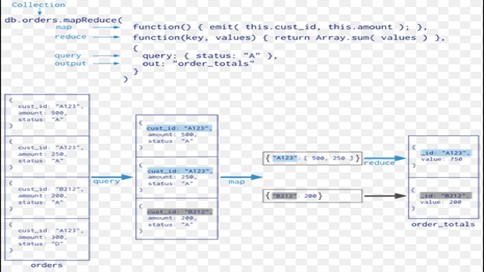
a) MapReduce
MapReduce is a powerful and flexible tool for aggregating data. It can solve problems which are complex in nature and express using the aggregation framework query language.
It splits up a problem, sends chunks of it to different machines, and lets each machine solve its part of the problem. When all the machines are finished, all the pieces of the solution are merged back into a full solution.

b) Single Purpose Aggregation Operations
For a number of common single purpose aggregation operations like returning a count of matching documents, returning the distinct values for a field, and grouping data based on the values of a field; MongoDB provides special purpose database commands.
All of these operations aggregate documents from a single collection. Though these operations provide simple access to common aggregation processes, they lack the flexibility and capabilities of the aggregation pipeline and MapReduce.
5. Indexes
Indexes are special data structures that store a small portion of the collection’s data set in an easy to traverse form. The index stores the value of a specific field or set of fields, ordered by the value of the field. The ordering of the index entries supports efficient equality matches and range-based query operations. In addition, MongoDB can return sorted results by using the ordering in the index. The following diagram illustrates a query that selects and orders the matching documents using an index:

Indexes are used for better query performance. They are created on fields which appear often in queries(_id) and for operations that return sorted results. MongoDB automatically creates a unique index on the _id field. Indexes have the following properties in MongoDB:
- Each index requires at least 8KB of data space.
- Adding an index has some negative performance impact for write operations. For collections with a high write-to-read ratio, indexes are expensive since each insert must also update any indexes.
- Collections with high read-to-write ratio often benefit from additional indexes the number of documents it must inspect.
- Replication When active, each index consumes disk space and memory. This usage grows over time can become significant. Perhaps, for better server space and performance management, it is good practice to track the growth of indexes.
Indexes support the efficient execution of queries. If an appropriate index exists for a query, MongoDB can use the index to limit
Replication provides redundancy and increases data availability. With multiple copies of data on different database servers, replication protects a database from the loss of a single server allows for recovery from hardware failure and service interruptions.

What is a replica?
A replica set is a group of MongoDB instances that host the same data set. One MongoDB, the primary, receives all write operations. All other instances, secondaries, apply operations from the primary so that they have the same data set (shown below). The primary accepts all write operations from clients. A replica set can have only one primary. To support replication, the primary records all changes to its data sets in its oplog (operations log).
Advantages of MongoDB over RDBMS:
- MongoDB is schema-less. It is a document database in which one collection holds different documents. But in RDBMS, you need to first design your tables, data structure, relations, and only then can you start coding.
- There may be a difference between the number of fields, content, and size of the document from one to other. But in RDBMS, every record must adhere to a particular predefined schema.
- MongoDB is horizontally scalable i.e we can add more servers (sharding) but RDBMS is only vertically scalable i.e increasing RAM.
- MongoDB emphasizes the CAP theorem (Consistency, Availability, and Partition tolerance) but RDBMS emphasizes ACID properties (Atomicity, Consistency, Isolation, and Durability).

- MongoDB supports JSON query language along with SQL but RDBMS supports SQL query language only.
- MongoDB is easy to set up, configure, and run in comparison to the RDBMS. It’s Java client is also very easy to use.
- MongoDB is almost 100 times faster than traditional database system like RDBMS, which is slower in comparison with the NoSQL databases.
- There is no support for complex joins in MongoDB, but RDBMS supports complex joins, which can be difficult to understand and take too much time to execute.
- MongoDB uses internal memory for storing working sets resulting in faster access time.
- MongoDB supports deep query-ability i.e we can perform dynamic queries on documents using the document-based query language that’s nearly as powerful as SQL.
- In MongoDB, Conversion/mapping of application objects to database objects is not needed.

Advantages of using MongoDB
As you can see from the above representation, when the number of queries hitting the server increases, MongoDB is a clear winner. MongoDB is typically used for real-time analytics where latency is low and availability requirements very high. MongoDB has come to the forefront because of the need of organizations to analyze semi-structured, unstructured and geospatial data and because the structure of data is rapidly changing in today’s world. Traditional RDBMS systems are unable to cope with these demands fully as their inherent structure does not allow them to do so. Though changes are being made in RDBMS systems too, to cope with the explosion of data, databases like MongoDB with their document structure are best suited for dealing with today’s data.
Limitations of MongoDB?
MongoDB has some limitations which are listed below.
- Max document size is 16 MB.
- Max document nesting level: 100 (documents inside documents inside documents).
- The indexed field can’t contain more than 1024 bytes.
- Max 64 indexes per collection.
- Max 31 fields can be used to create a compound index.
- Full-text search and geo indexes are mutually exclusive.
- Limit of documents in a capped collection can’t be more than 2**32. Otherwise, a number of documents are unlimited.
- On windows, MongoDB can’t store more than 4 TB of data (8 TB without journal)
- Max 12 nodes in a replica set.
- Max 7 voting nodes in a replica set.
- To rollback, more than 300 MB of data manual intervention is needed.
- Group command doesn’t work in a sharded cluster.
- $isolated, $snapshot, geoSearch don’t work in a sharded cluster.
- You can’t refer to DB object in $where
- For sharding a collection it must be less than 256 GB.
- Individual (not multi) updates/removes in a sharded cluster must include shard key. Multi versions of these commands may not include shard key.